Sationary and Nonstationary Series
Macroeconomic Forecasting Lecture
2025-03-04
Univariate Analysis
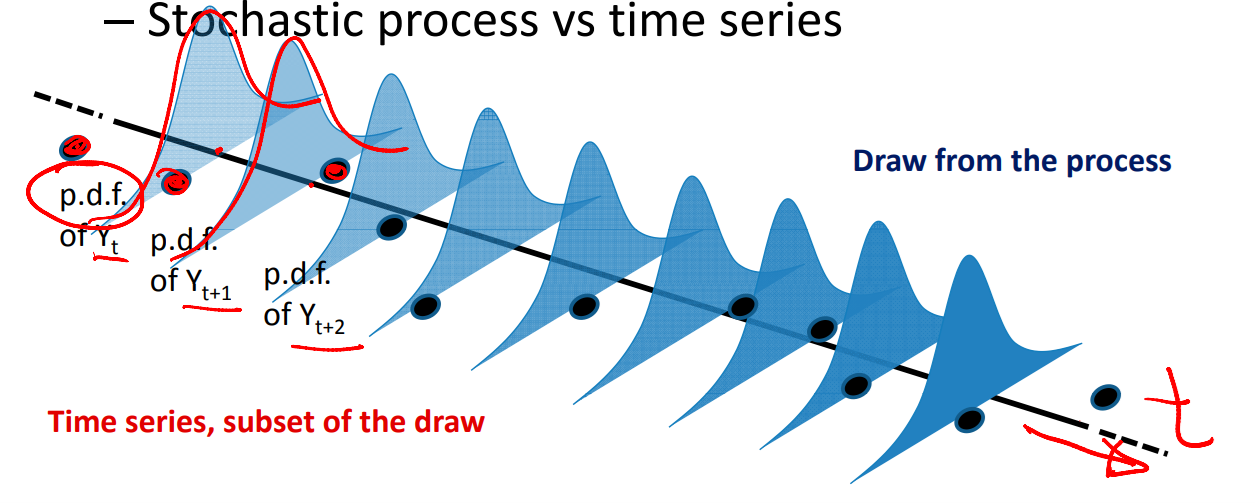
Each distribution is a draw from a random process.
Plot plot and plot your data
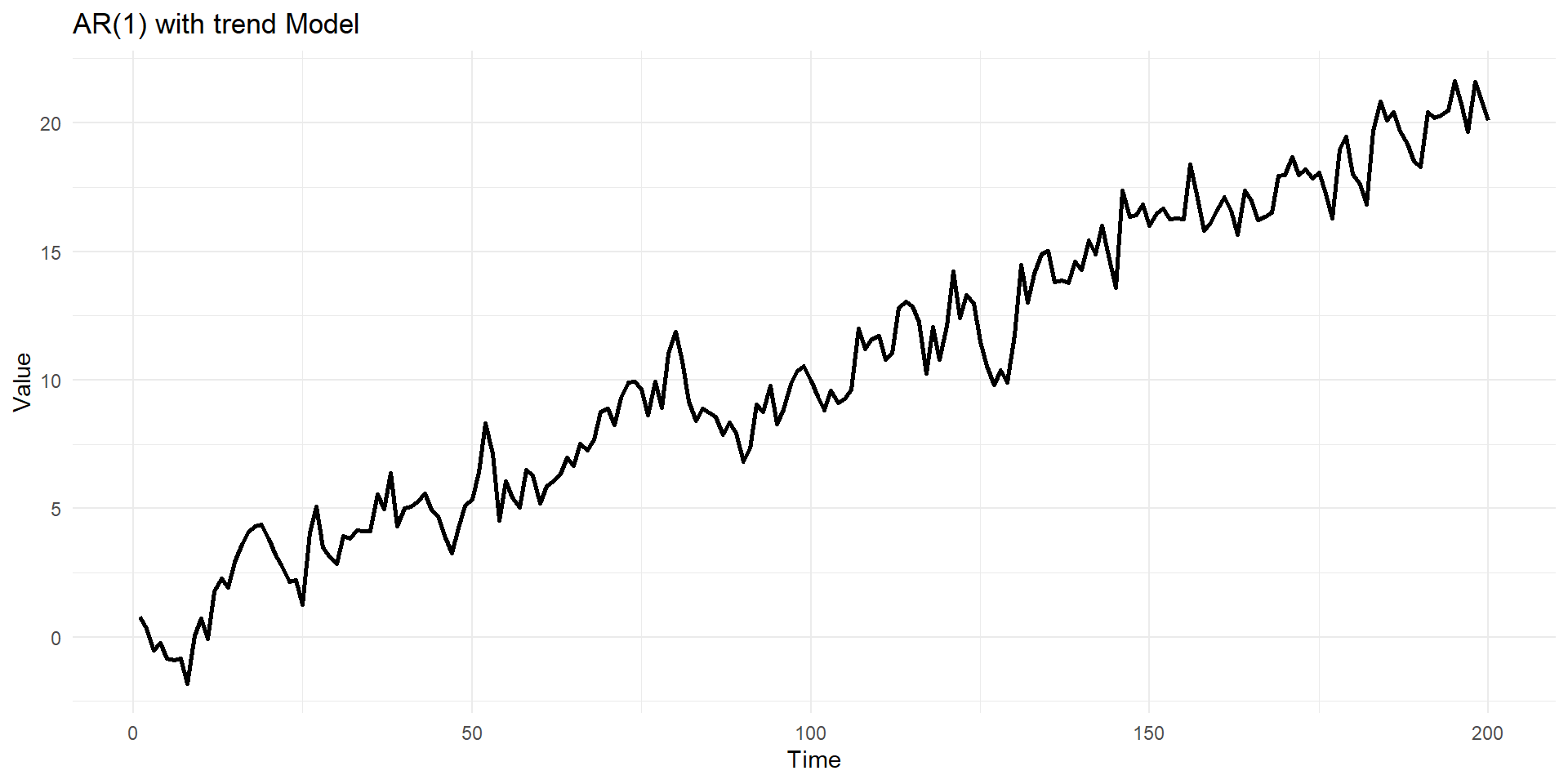
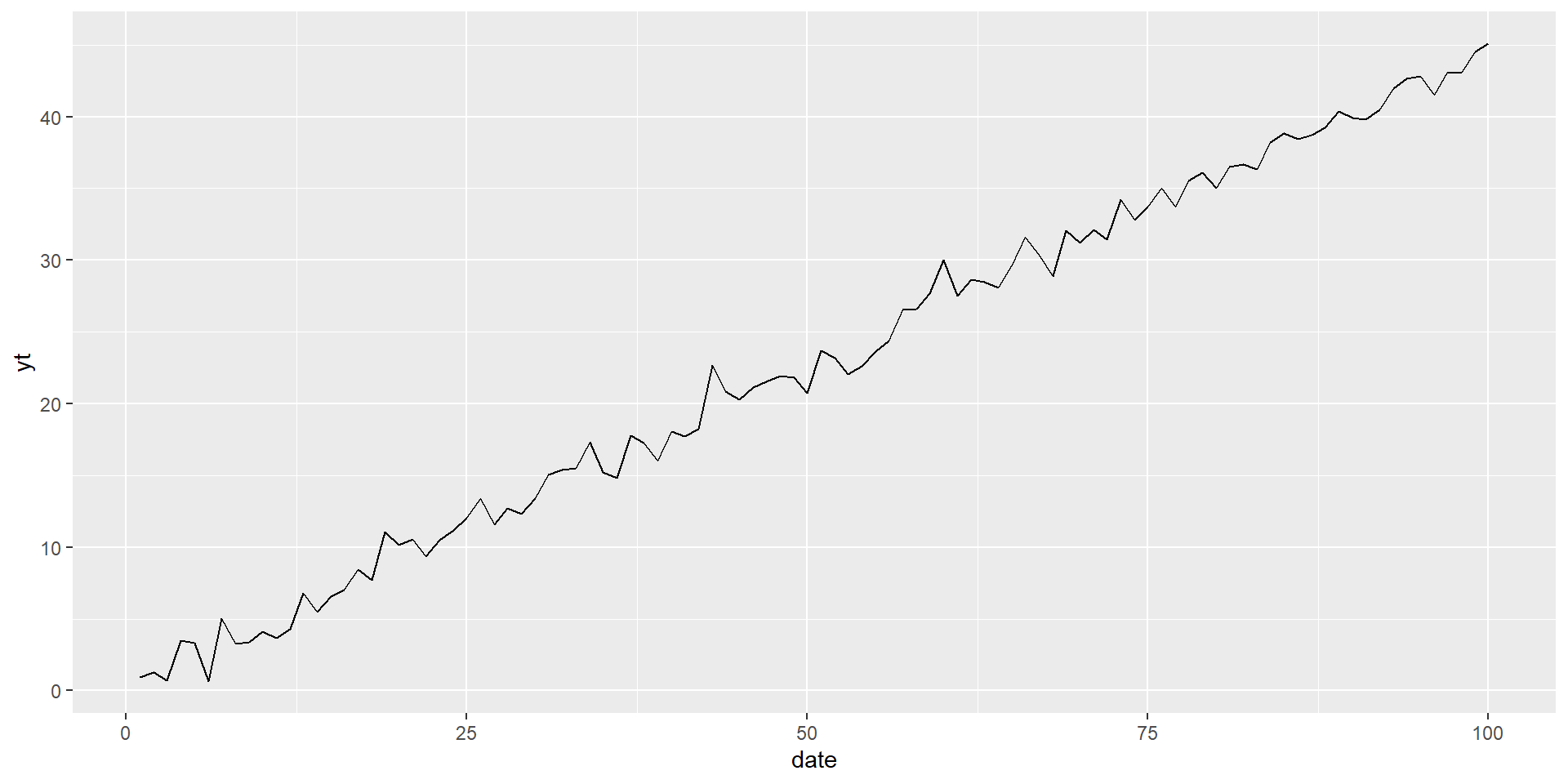
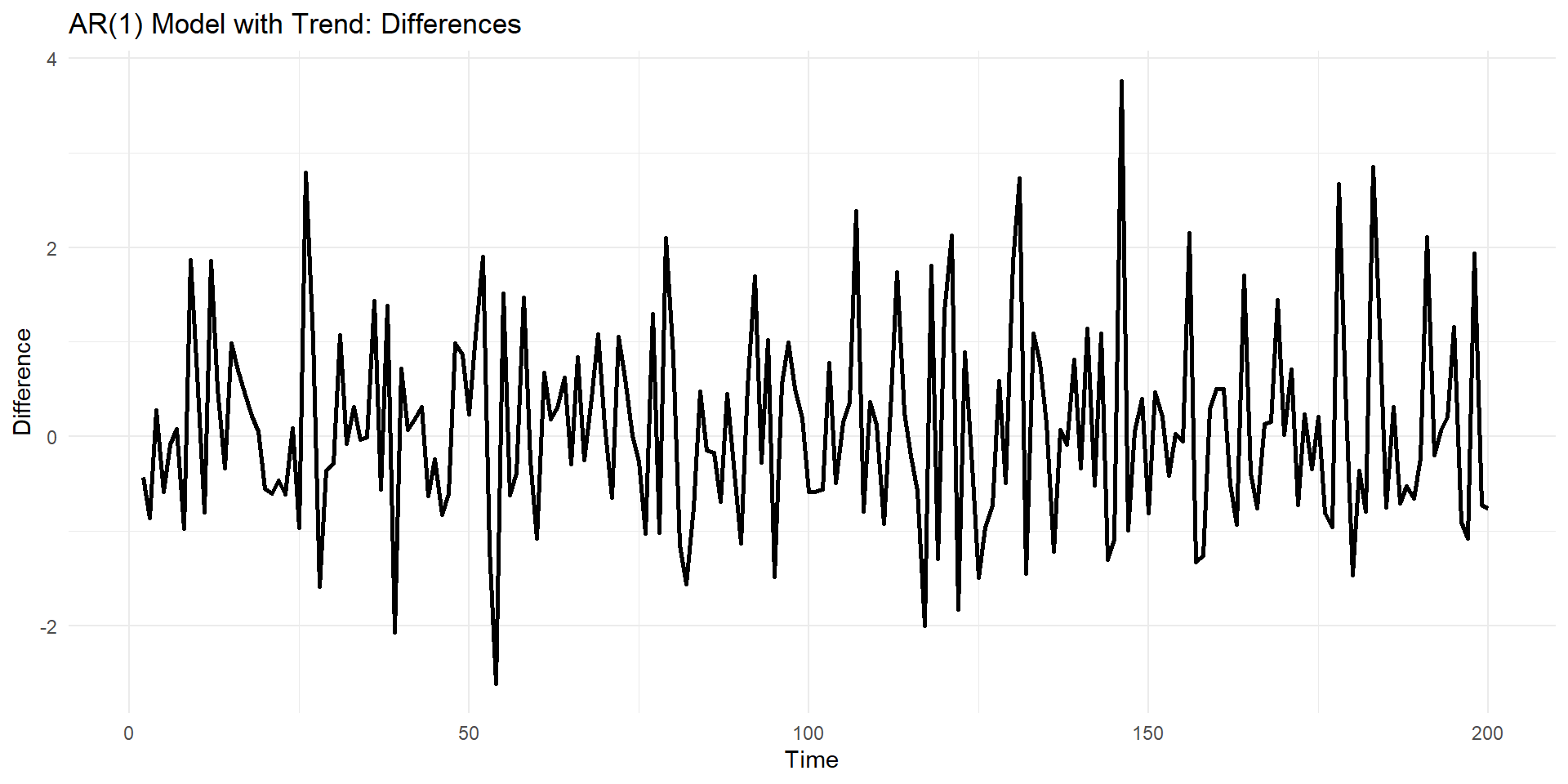
Differenced model of trend variable (third case)
Difference can remove the trend.
\(y_t^{*}=y_t-y_{t-1}\)
NULL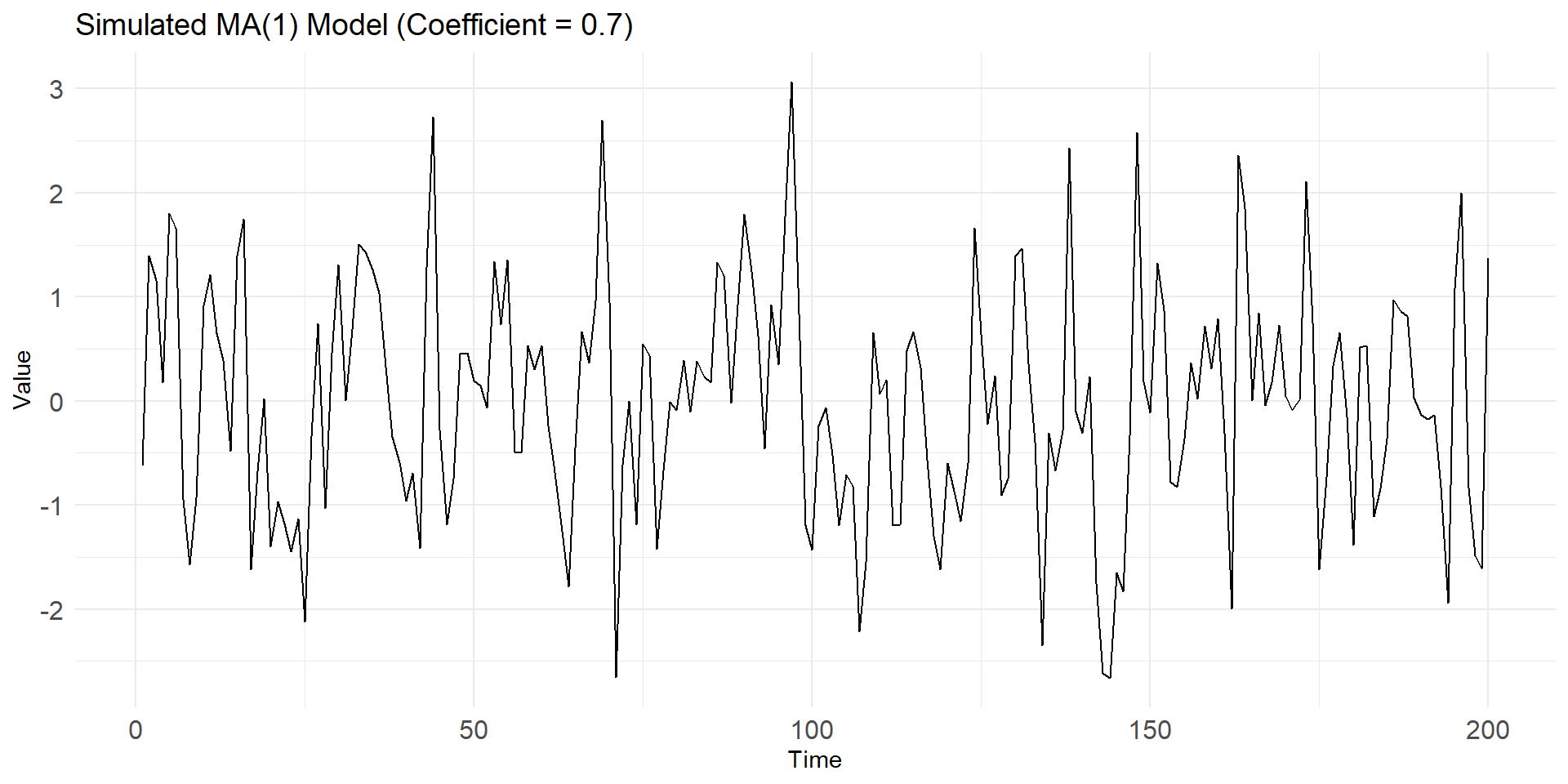
NULL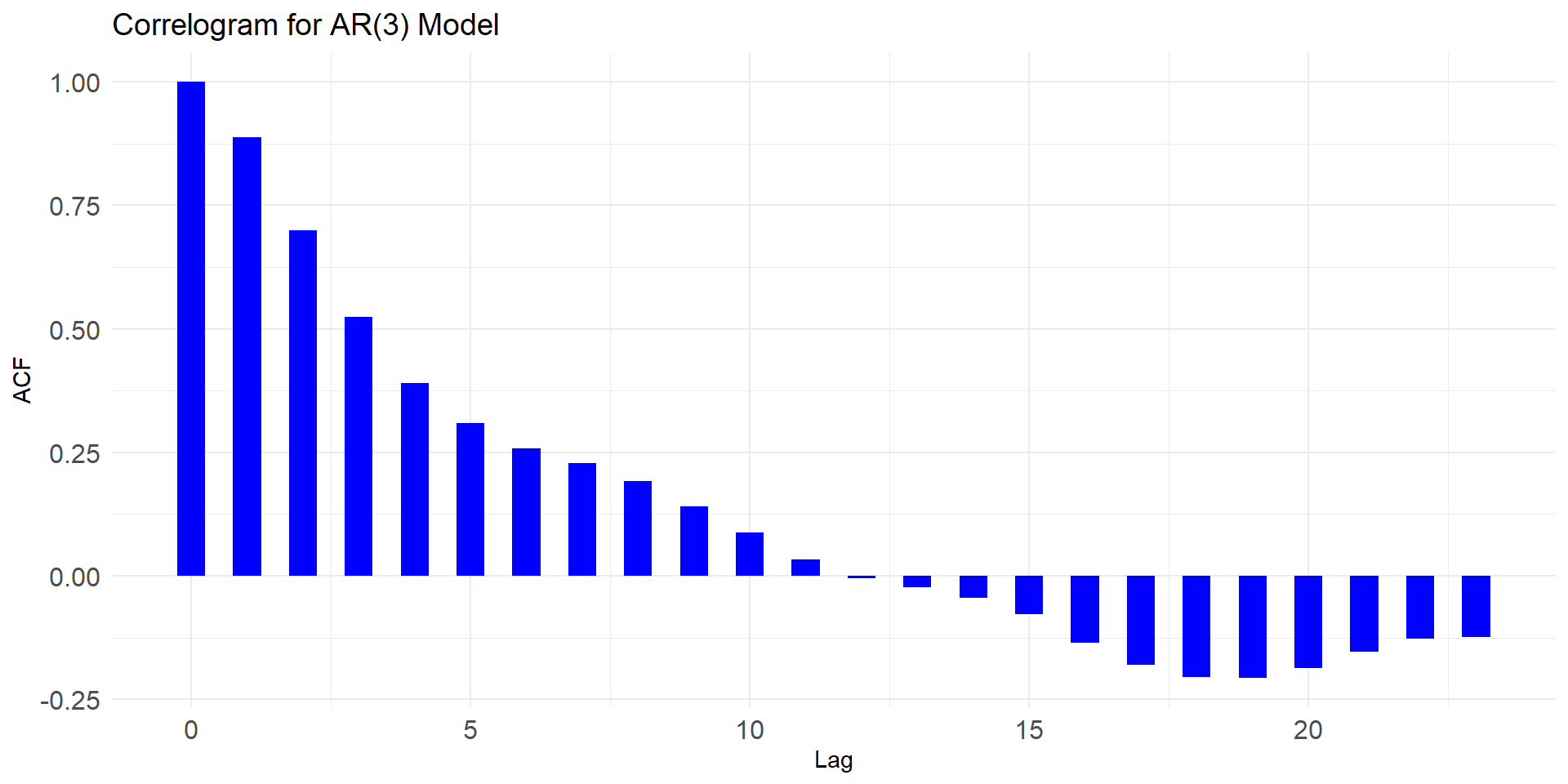
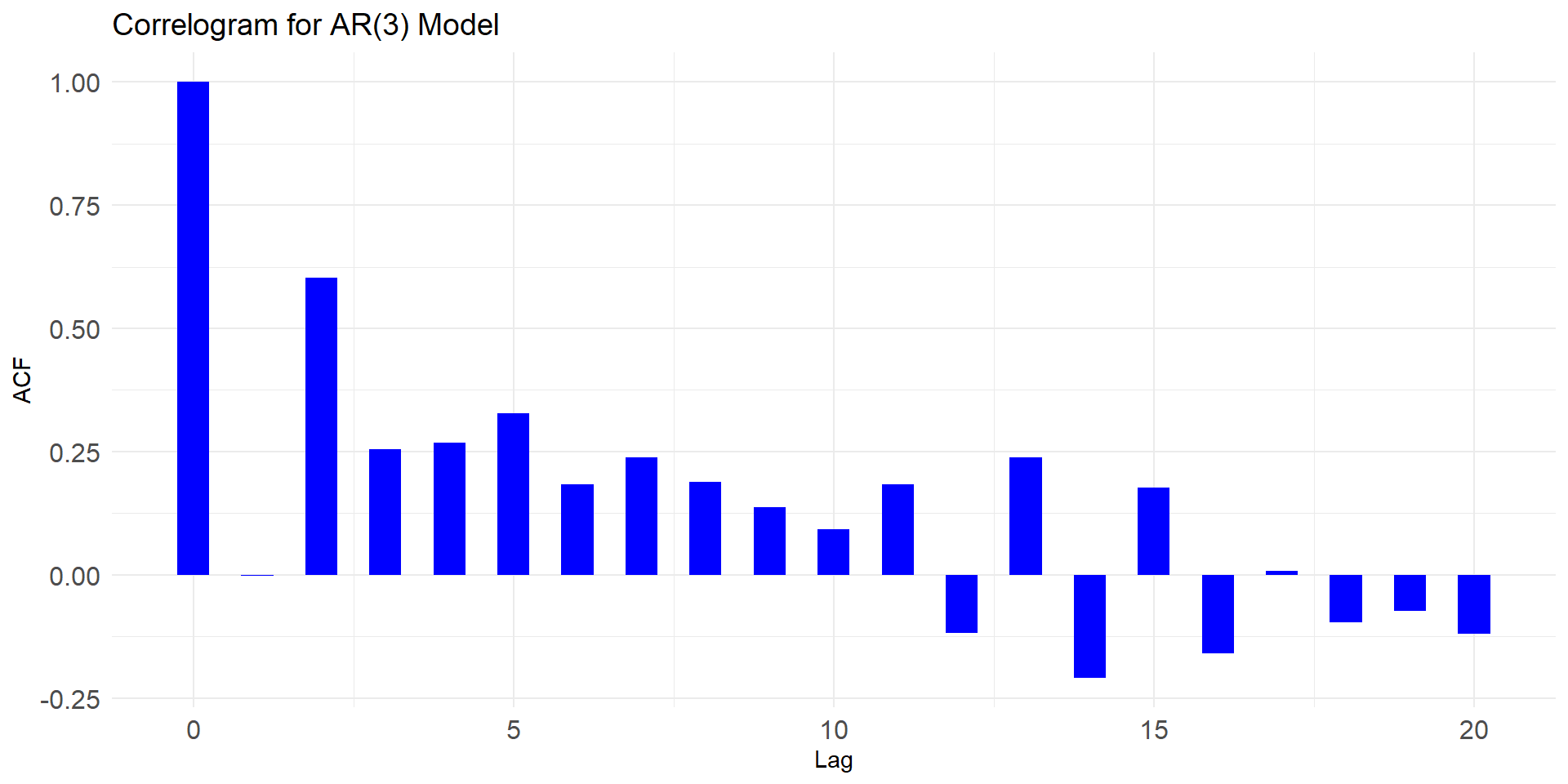
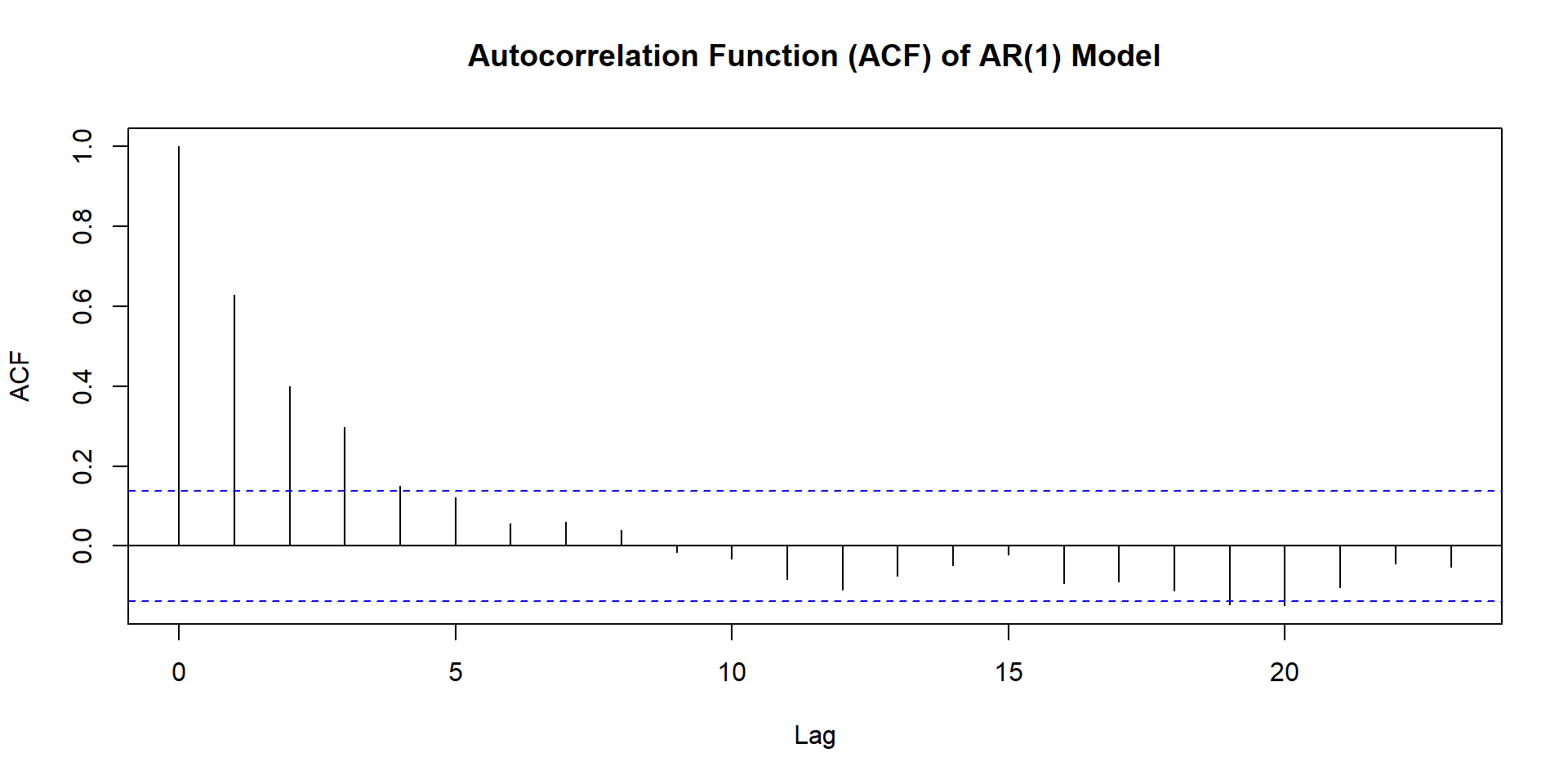
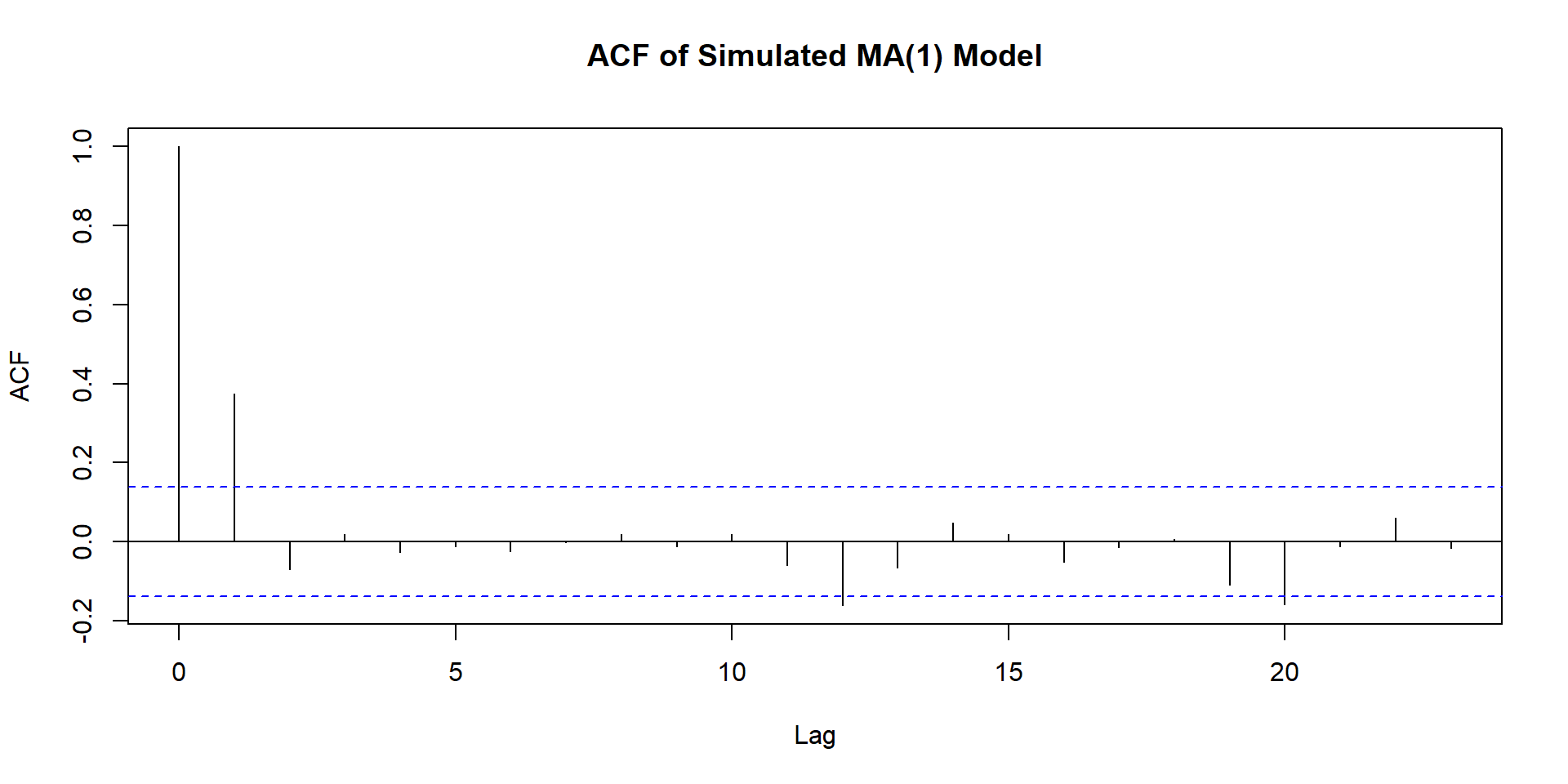
Patterns for PACF
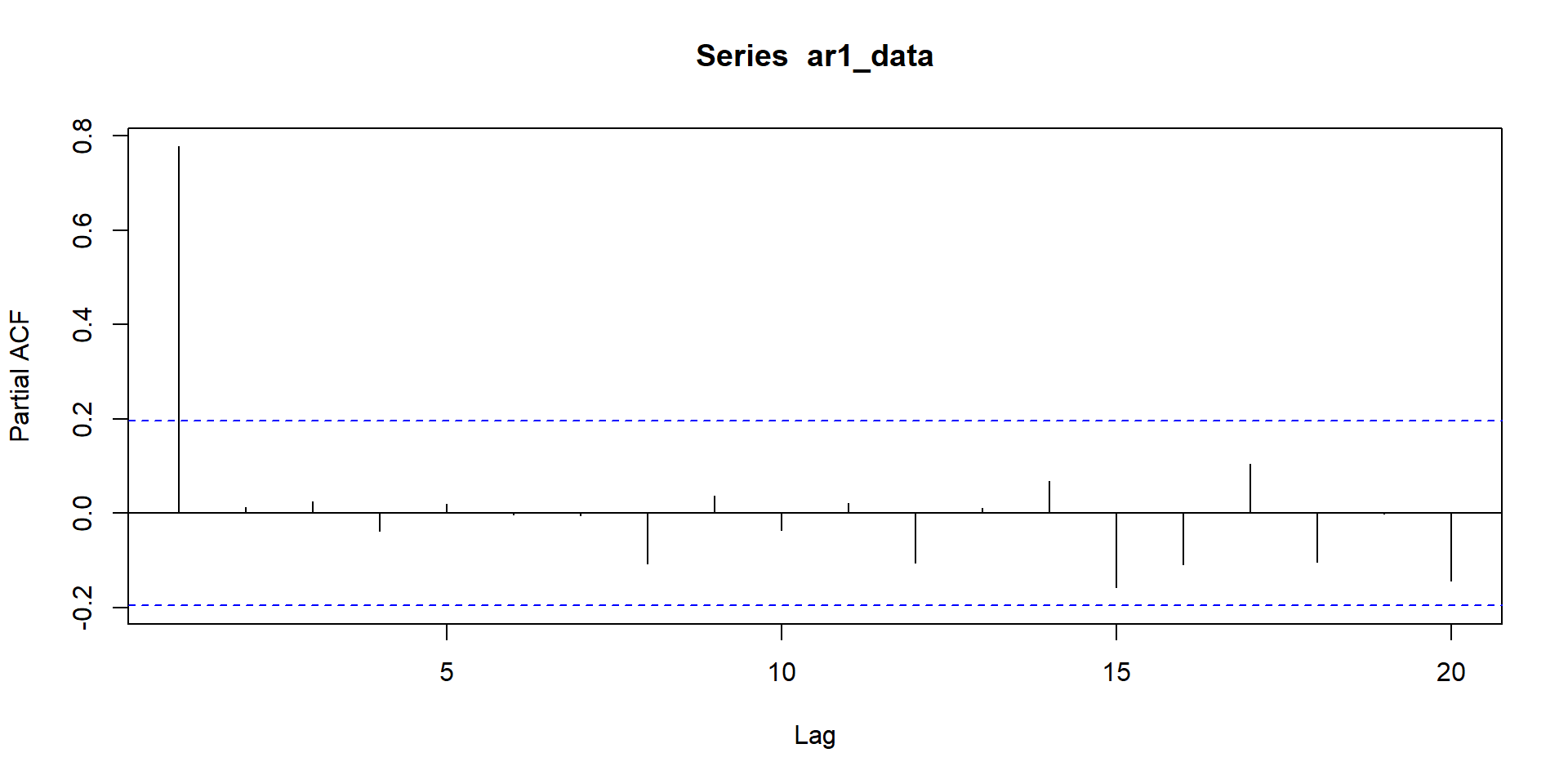
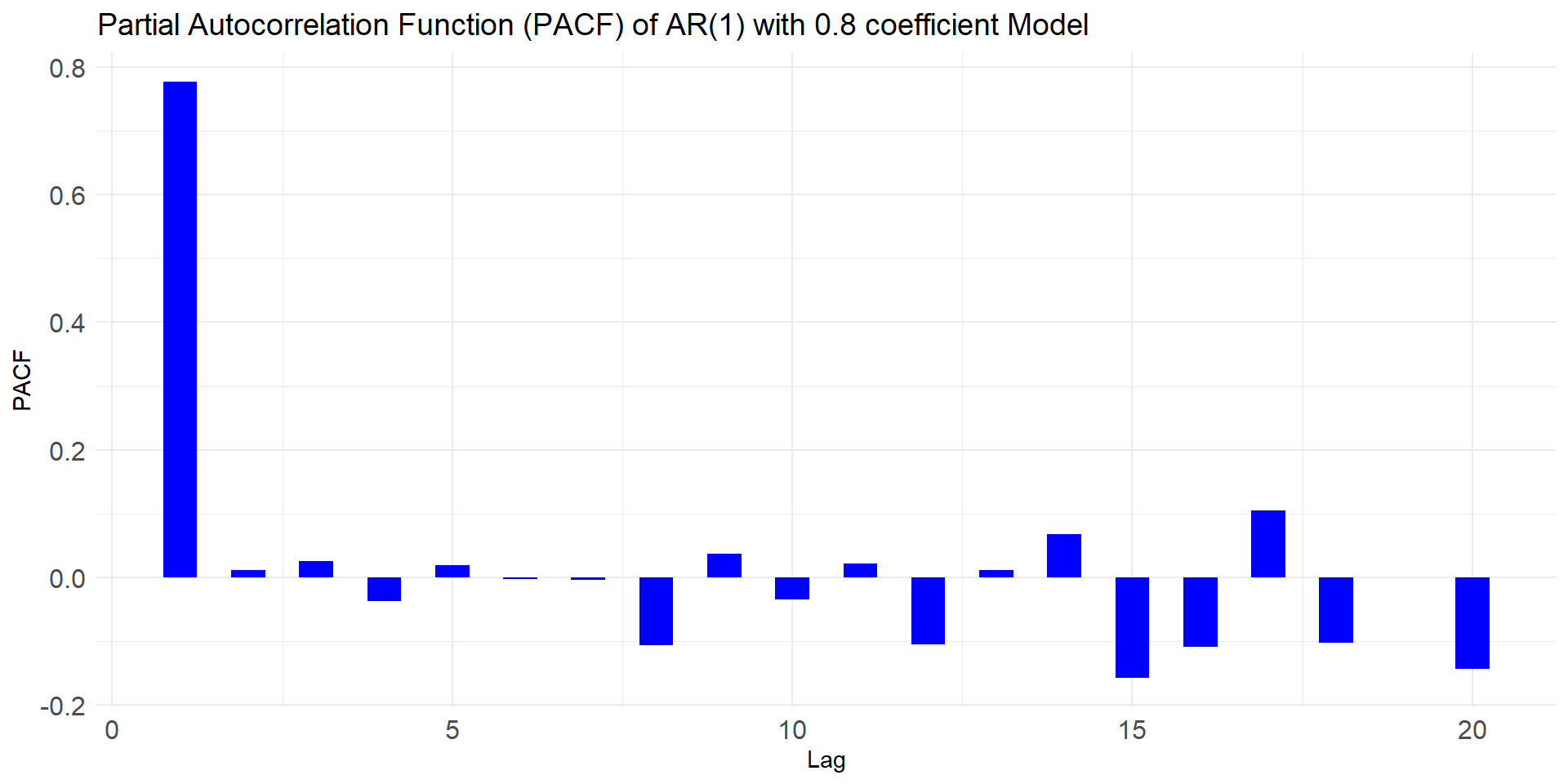
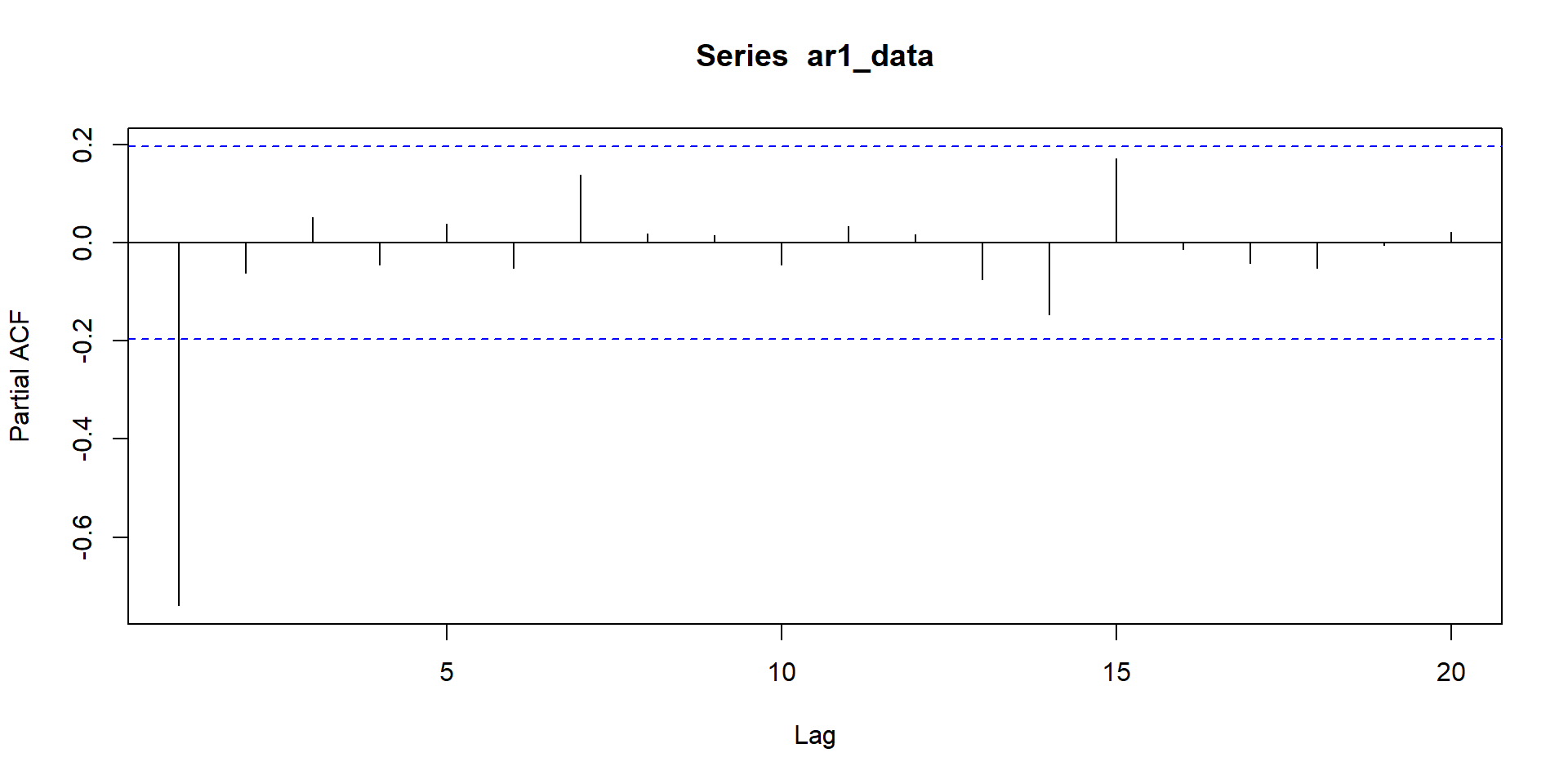

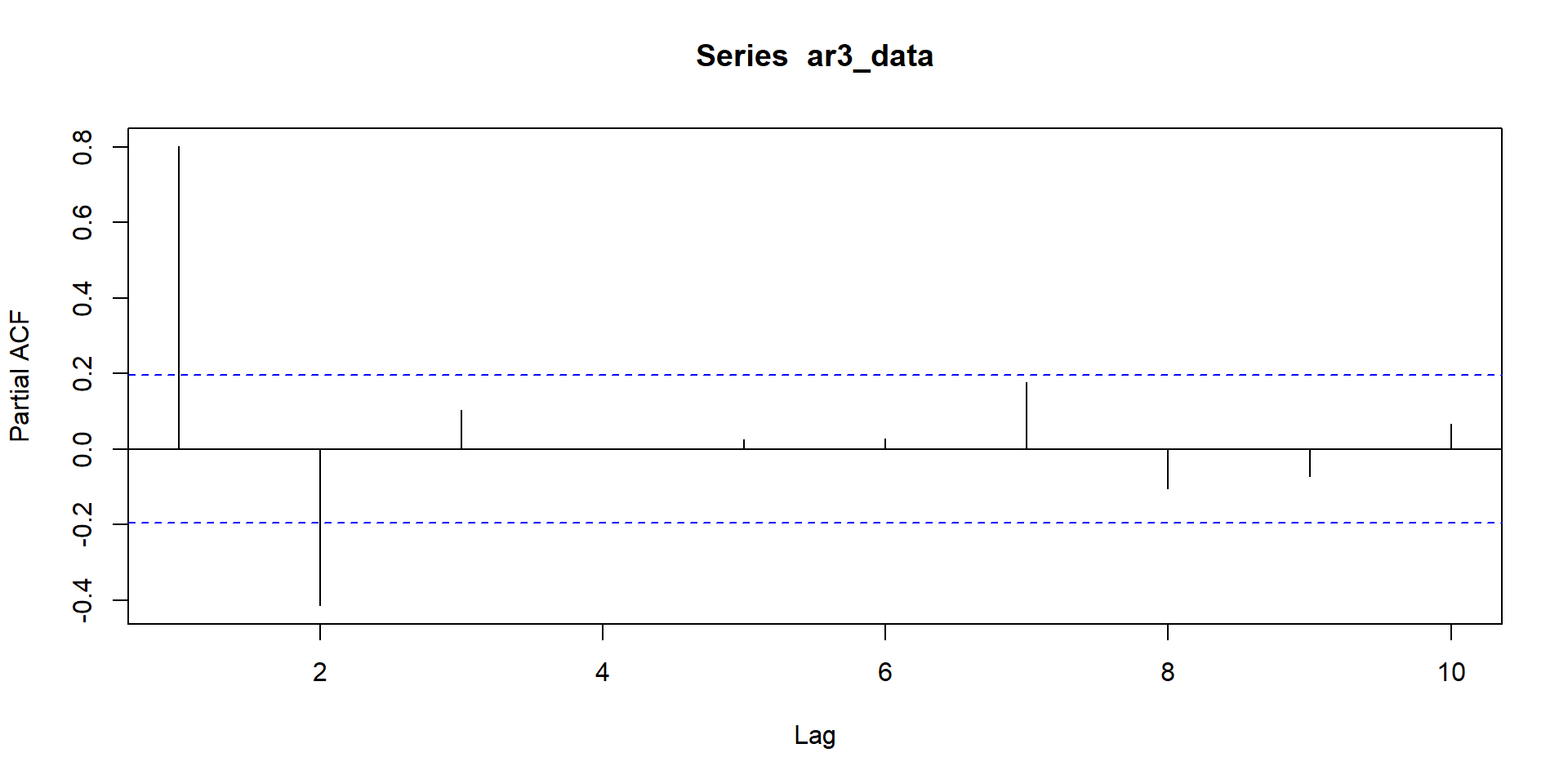
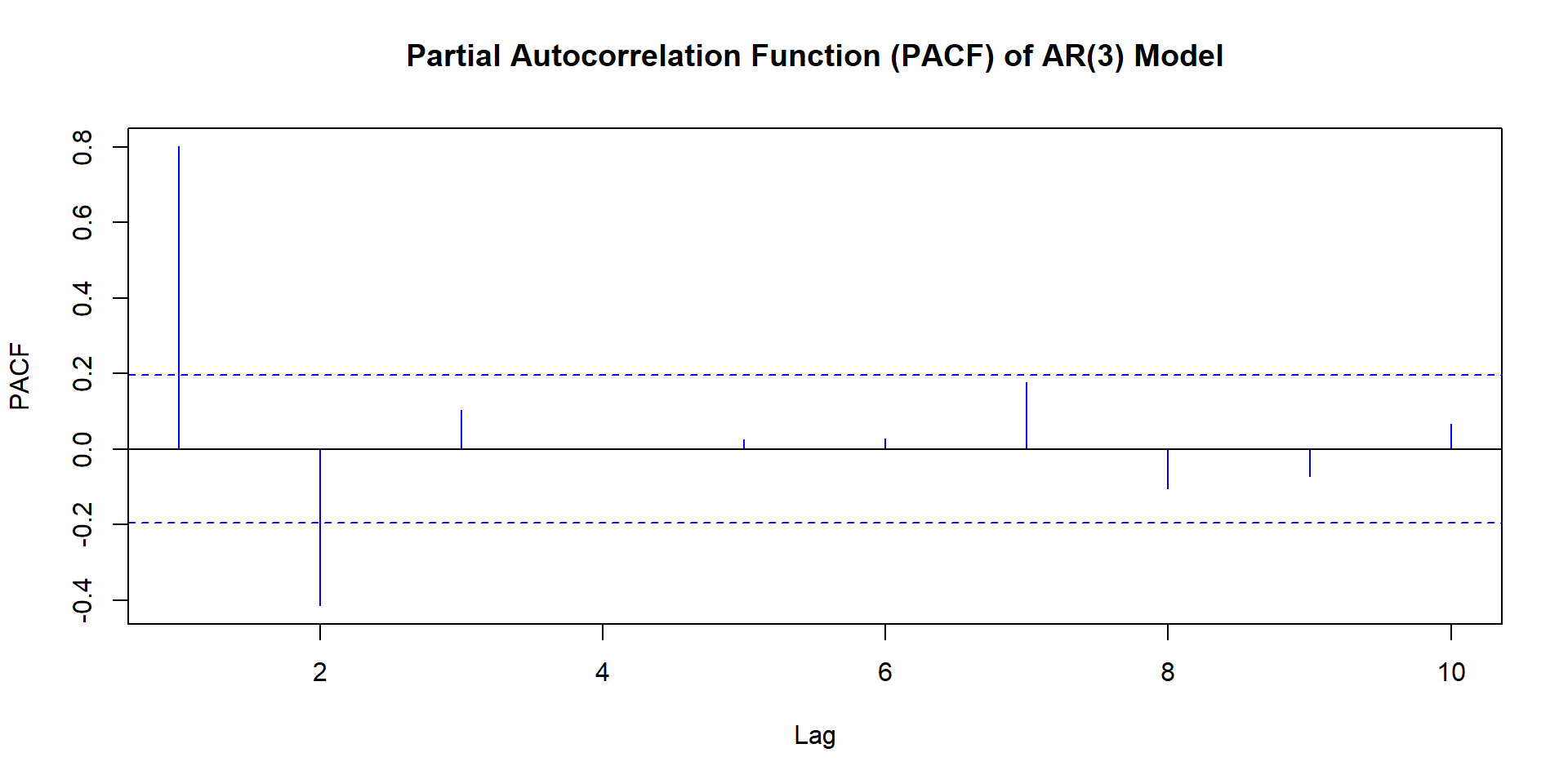
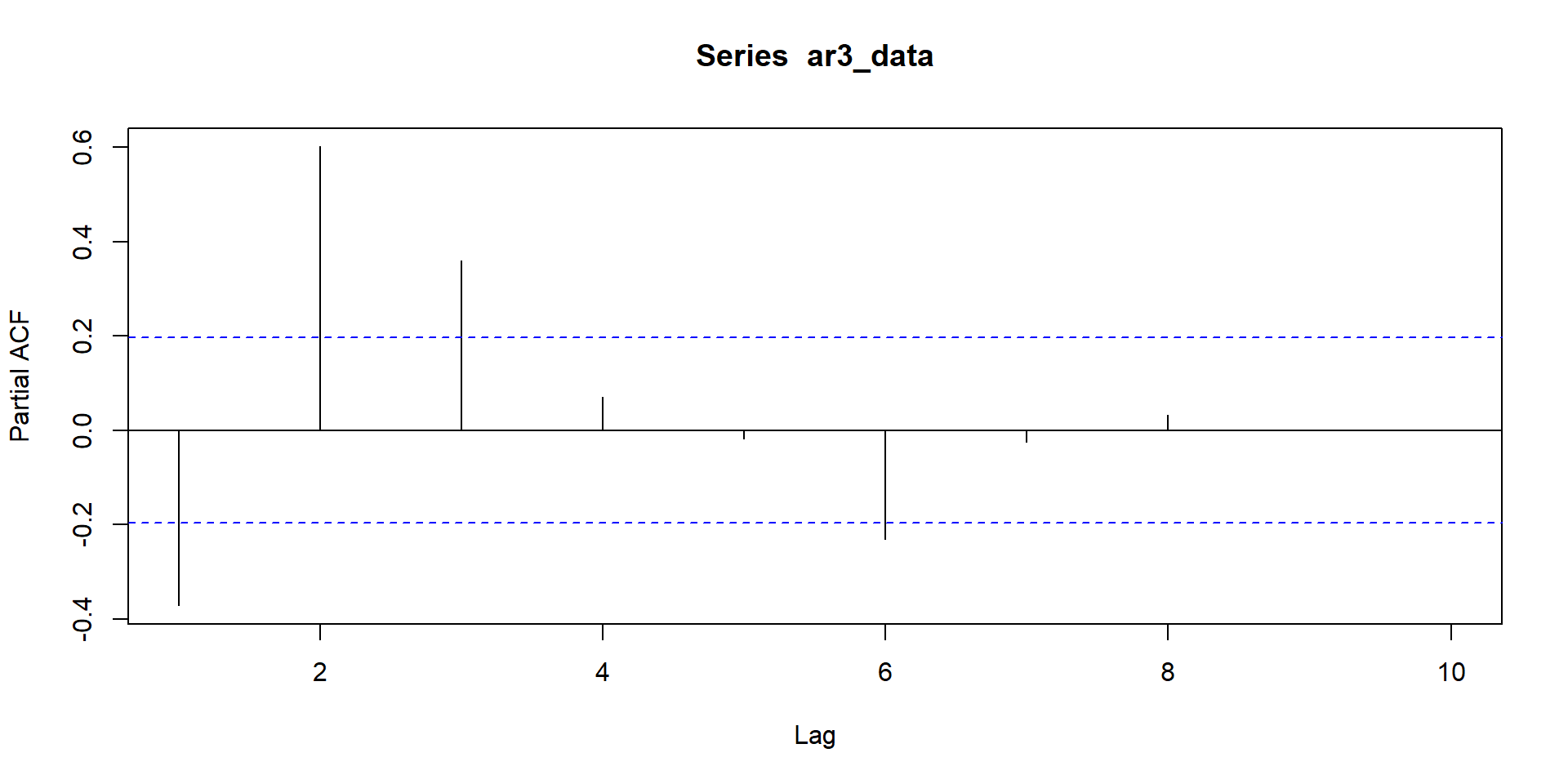

ACF and PACF for MA(3)

Summary Table Pattern
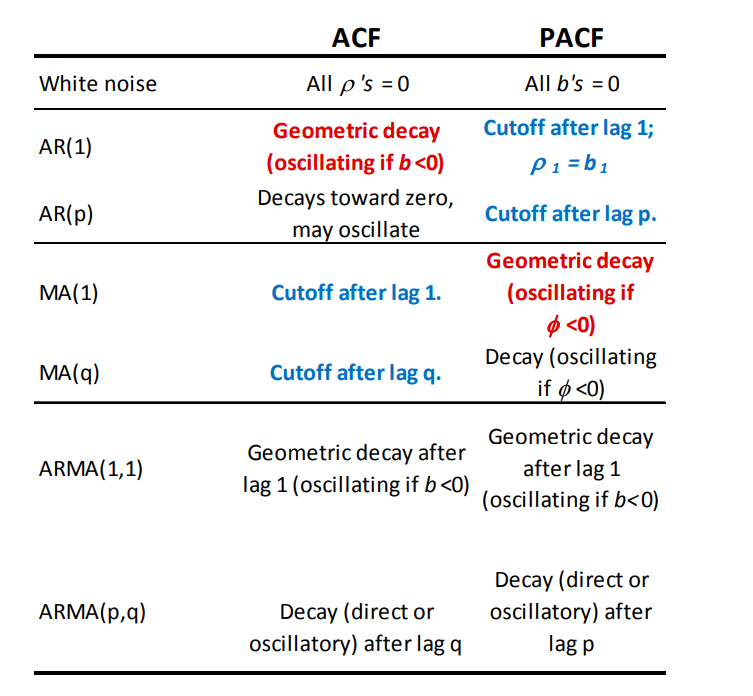
Pattern for model identification
Learning all above with simulated data
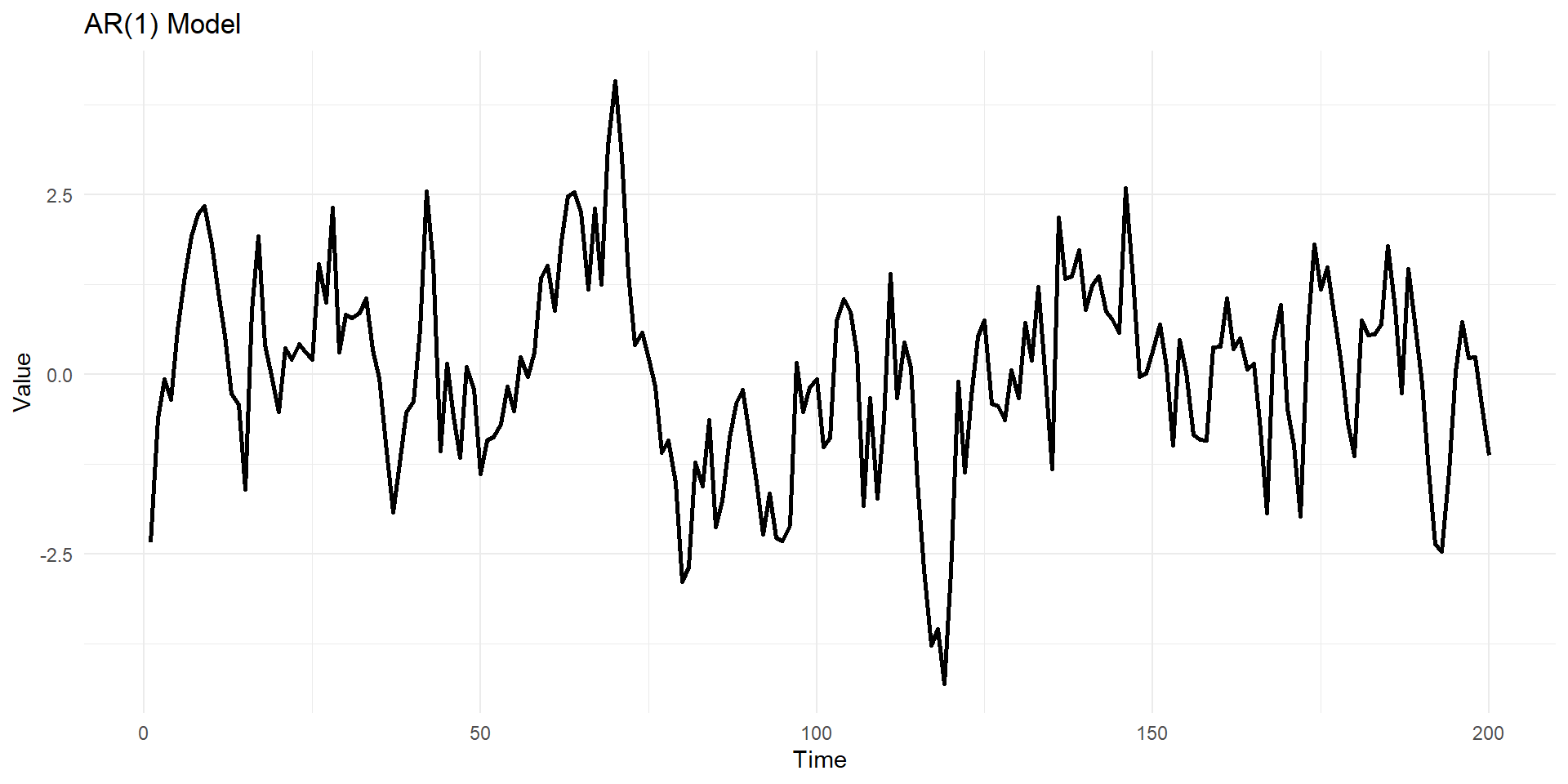
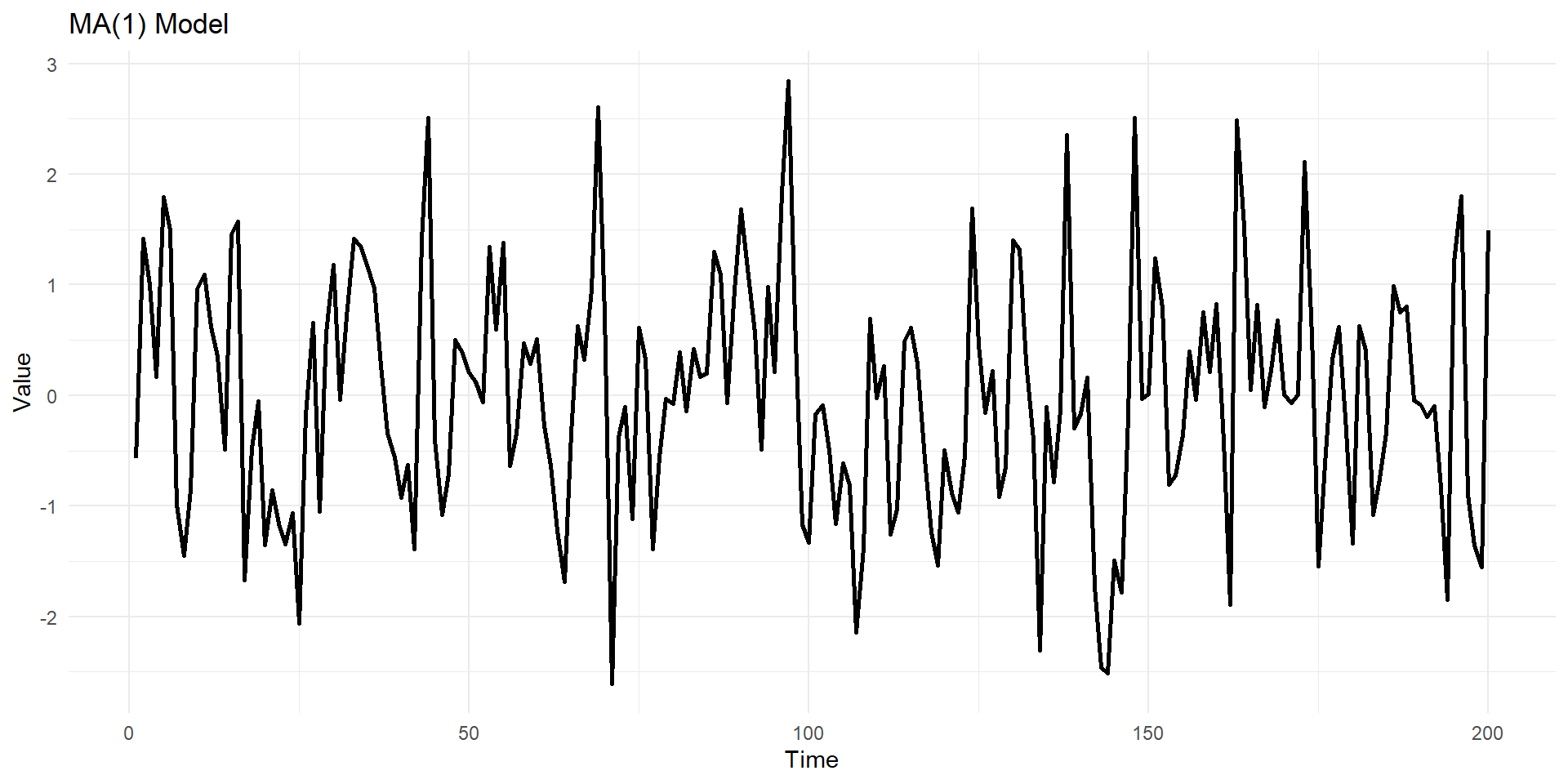
Lets simulate MA(1), AR(1) series in R
# Set the parameters
mu <- 0 # Mean of the series
theta <- 0.6 # Moving average coefficient
n <- 200 # Number of time points
# Simulate data from the MA(1) model
set.seed(123) # For reproducibility
ma1_data <- arima.sim(model = list(ma = theta), n = n, mean = mu)
# Create a data frame with time series data
time_series_data <- data.frame(Time = 1:n, Value = ma1_data)
# Create a ggplot2 line plot
ggplot(time_series_data, aes(x = Time, y = Value)) +
geom_line(linewidth=1) +labs(title = "MA(1) Model ", x = "Time", y = "Value") +
theme_minimal()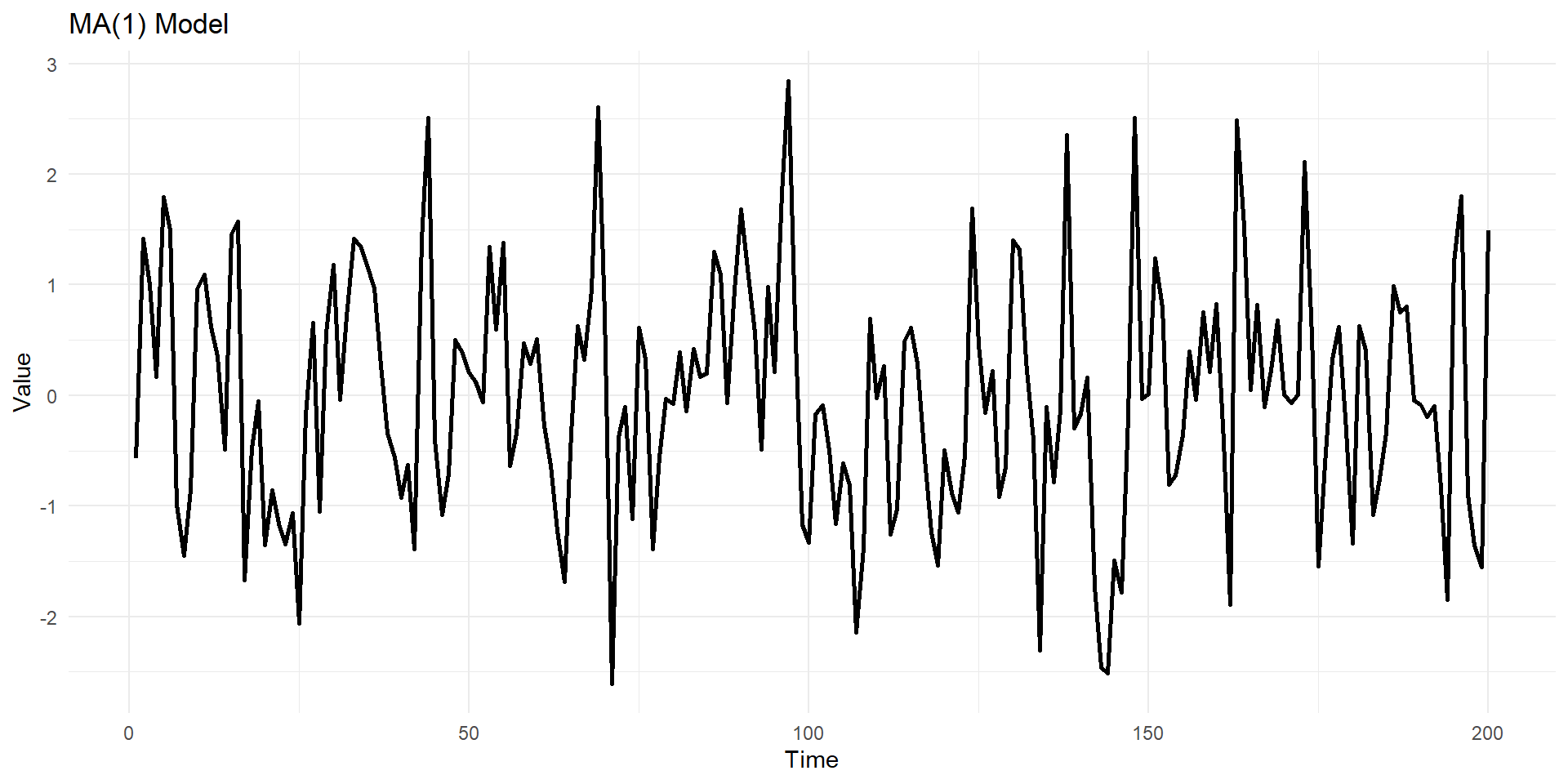
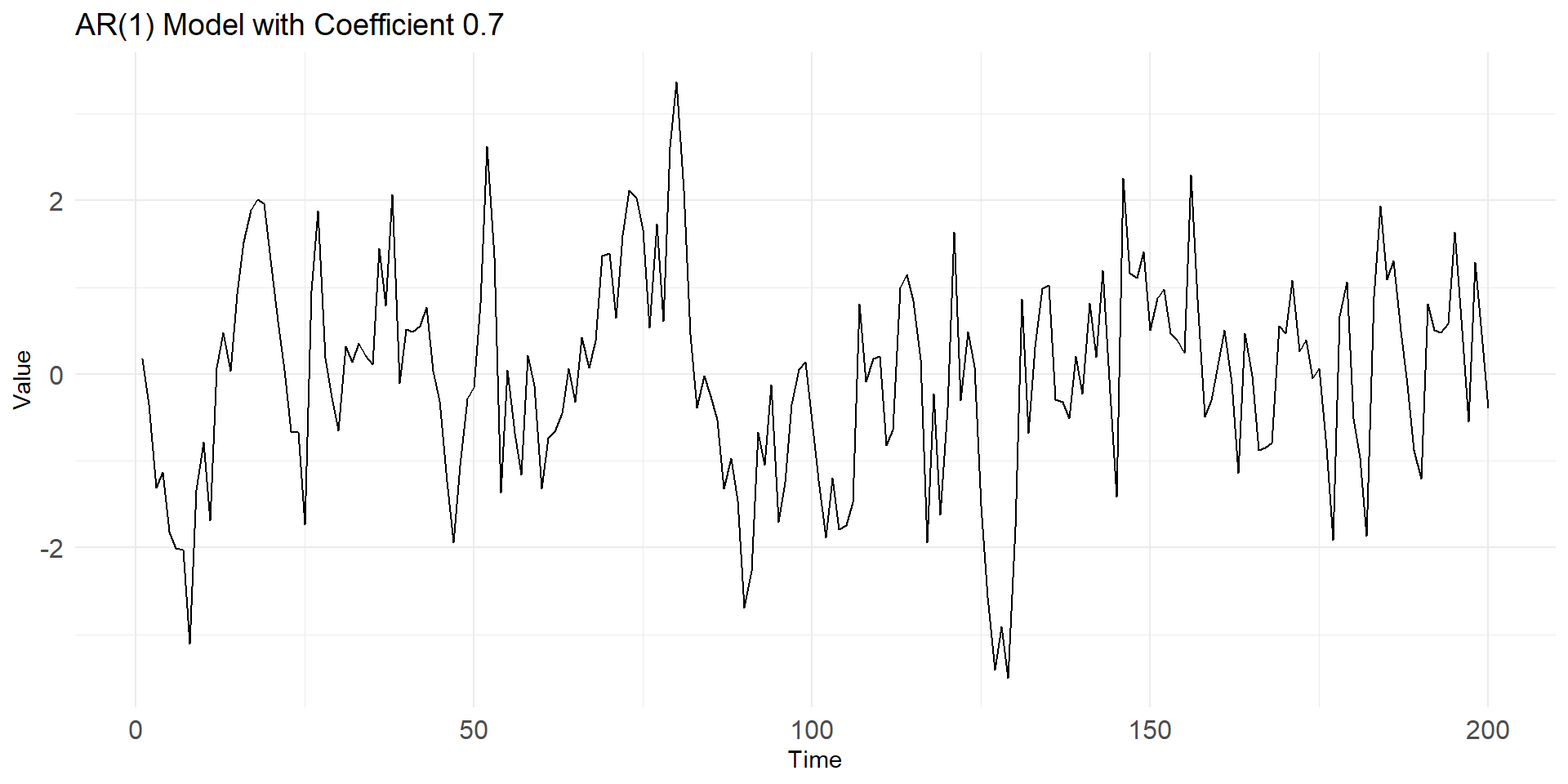
phi <- 0.8 # Autoregressive coefficient
n <- 200 # Number of time points
# Simulate data from the AR(1) model
set.seed(123) # For reproducibility
ar1_data <- arima.sim(model = list(ar = phi), n = n)
# Create a data frame with time series data
time_series_data <- data.frame(Time = 1:n, Value = ar1_data)
# Create a ggplot2 line plot
ggplot(time_series_data, aes(x = Time, y = Value)) +
geom_line(linewidth=1) +labs(title = "AR(1) Model ", x = "Time", y = "Value") +
theme_minimal()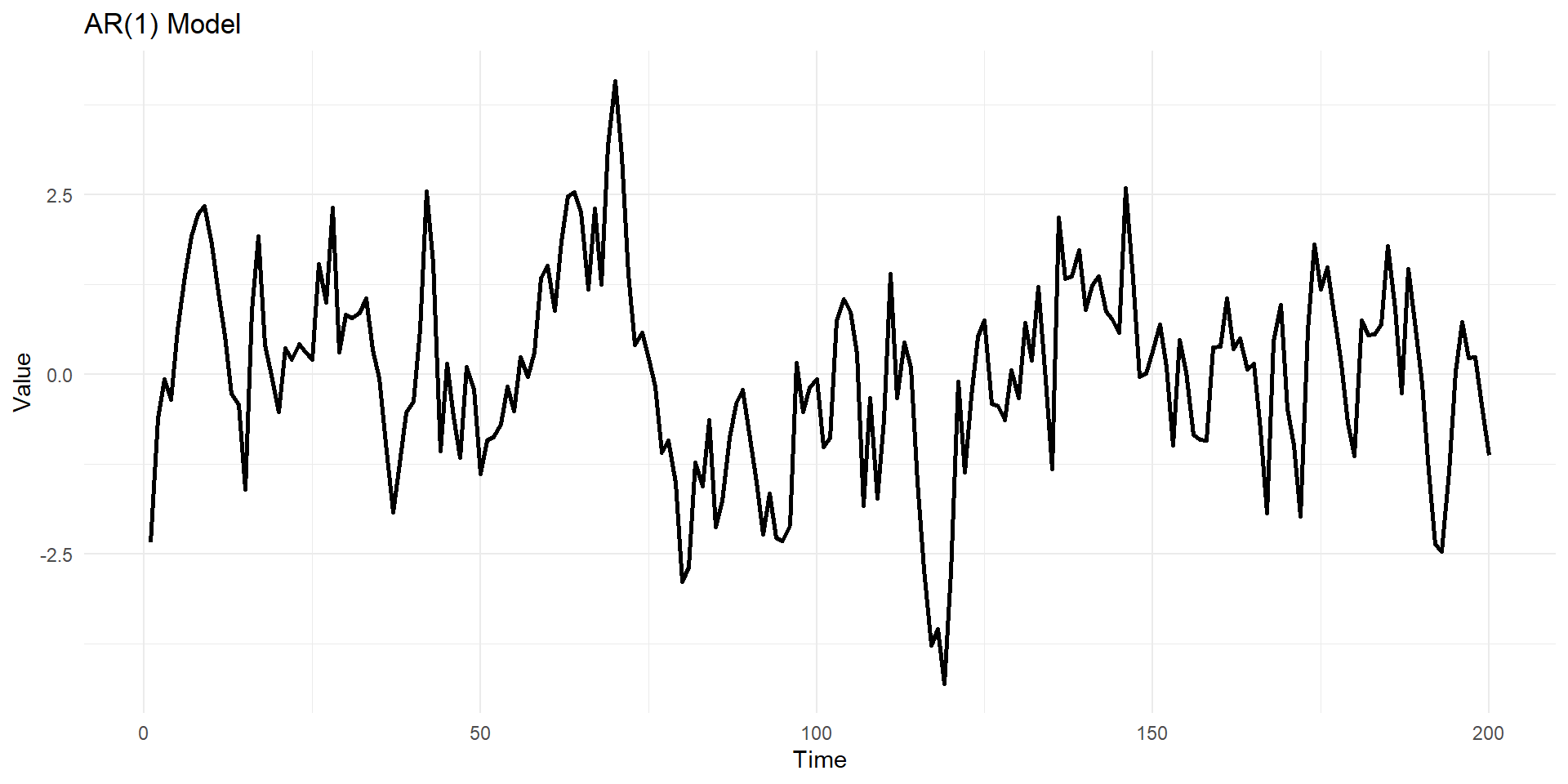
ACF and PACF of AR-1 and MA-`
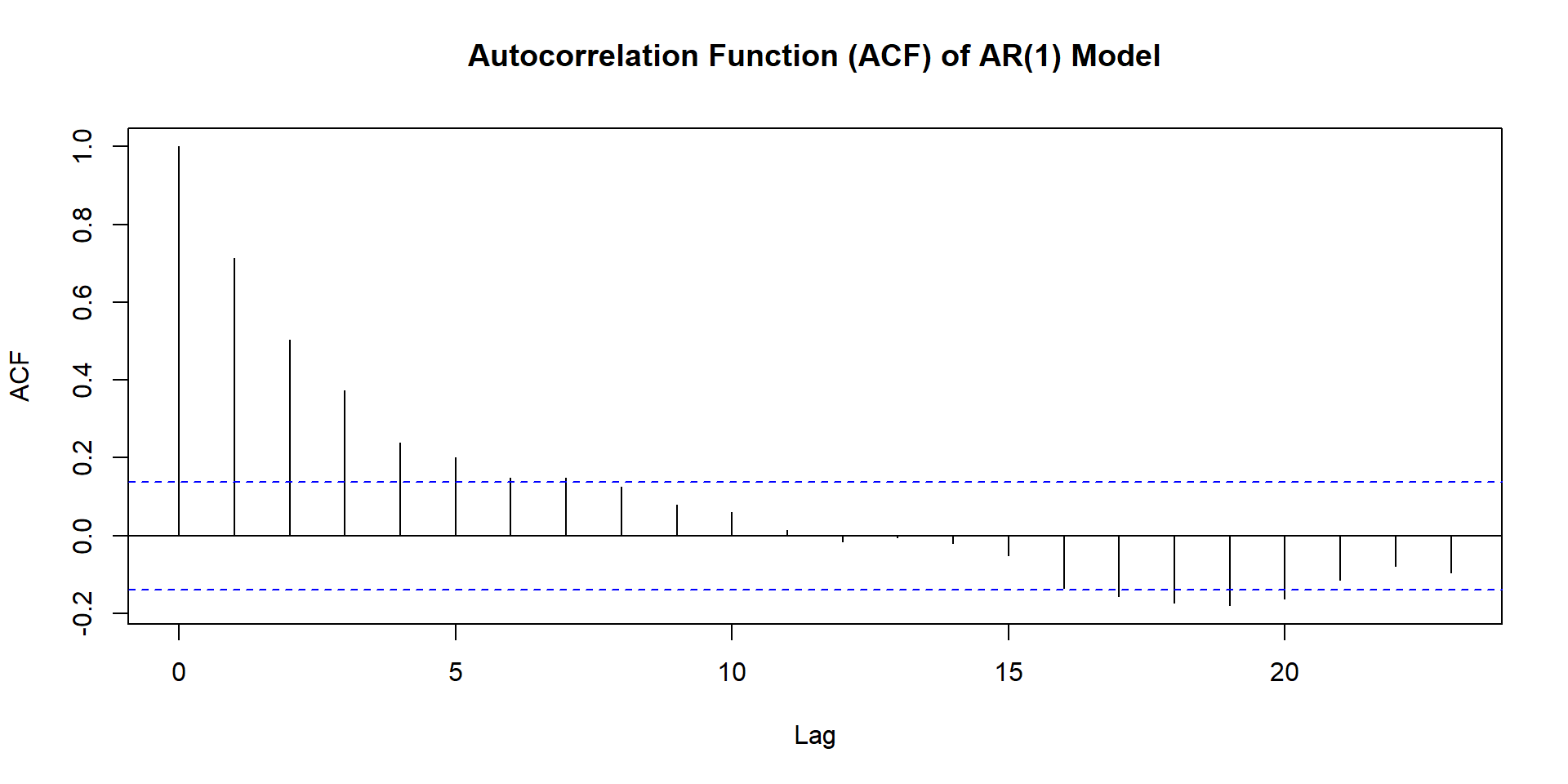
NULL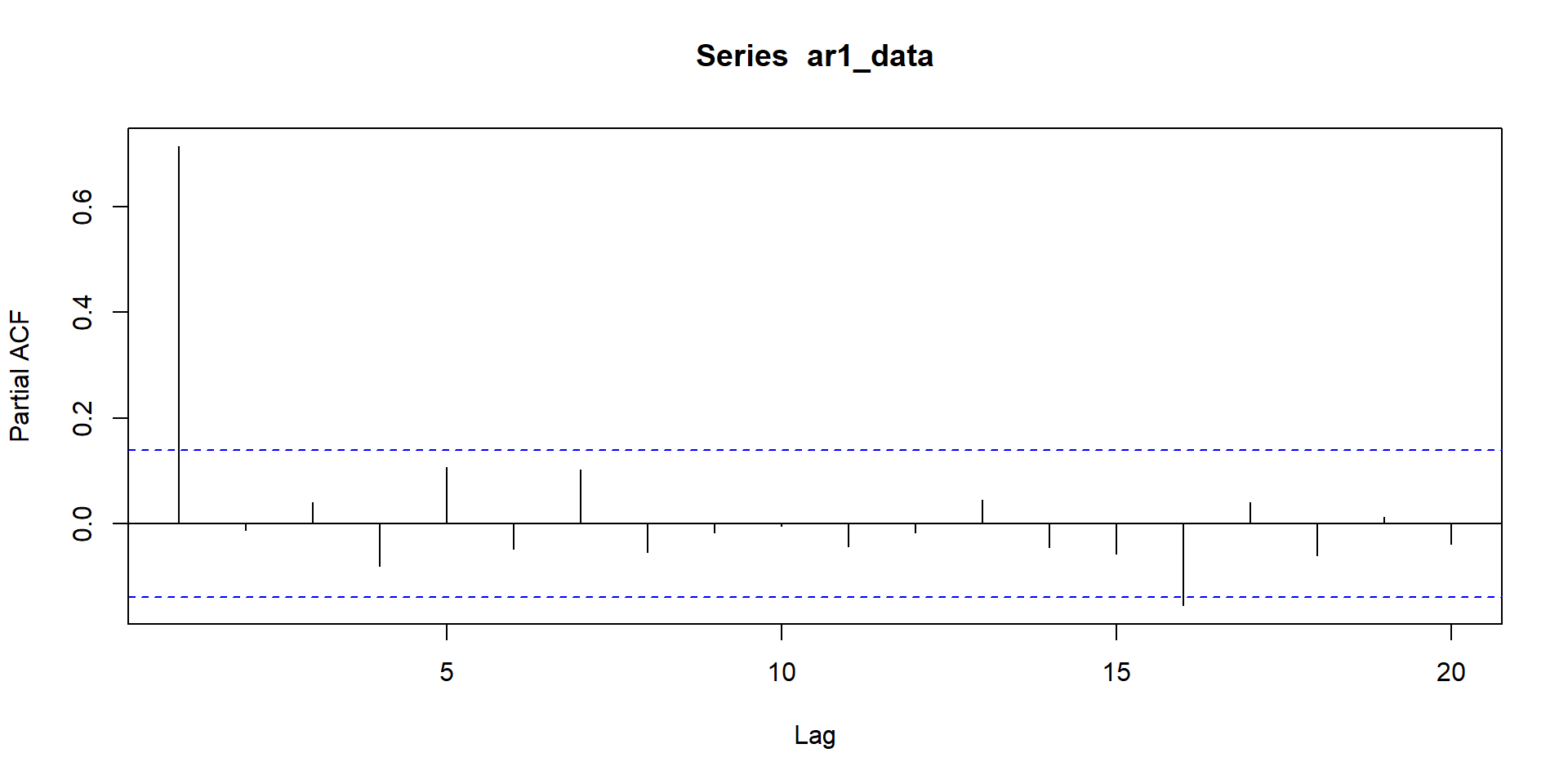
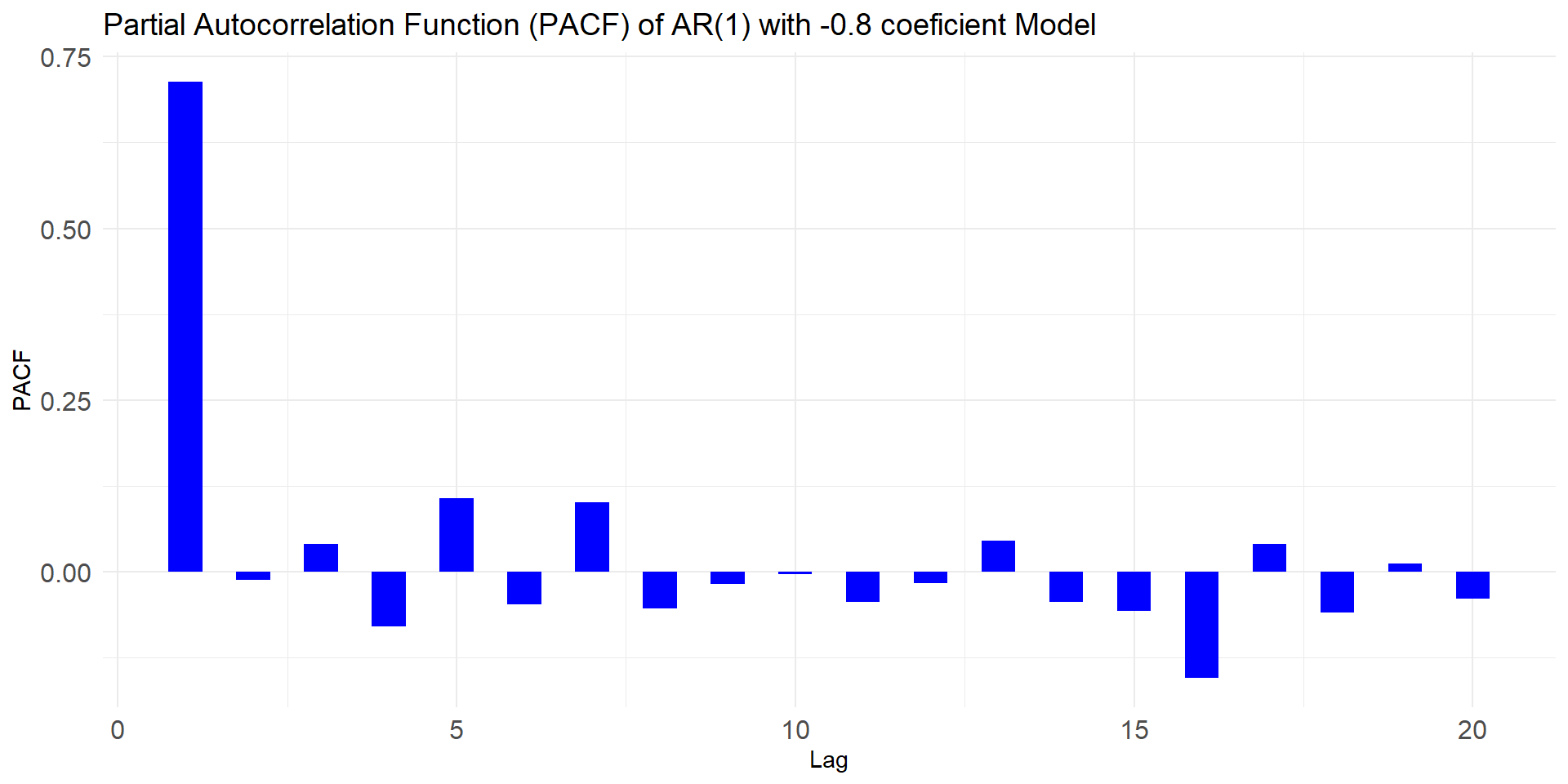
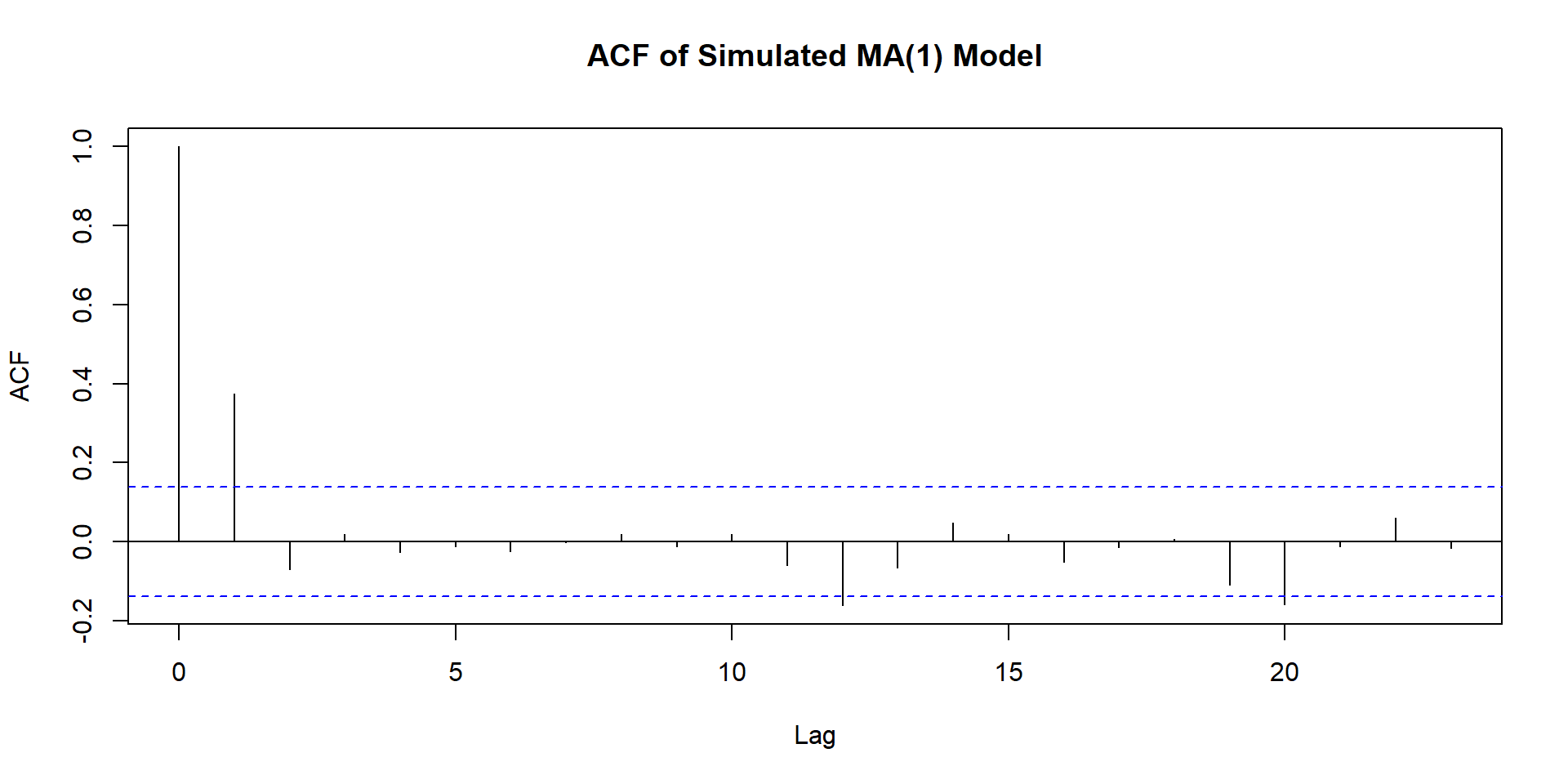
NULL
Pick pe_usa
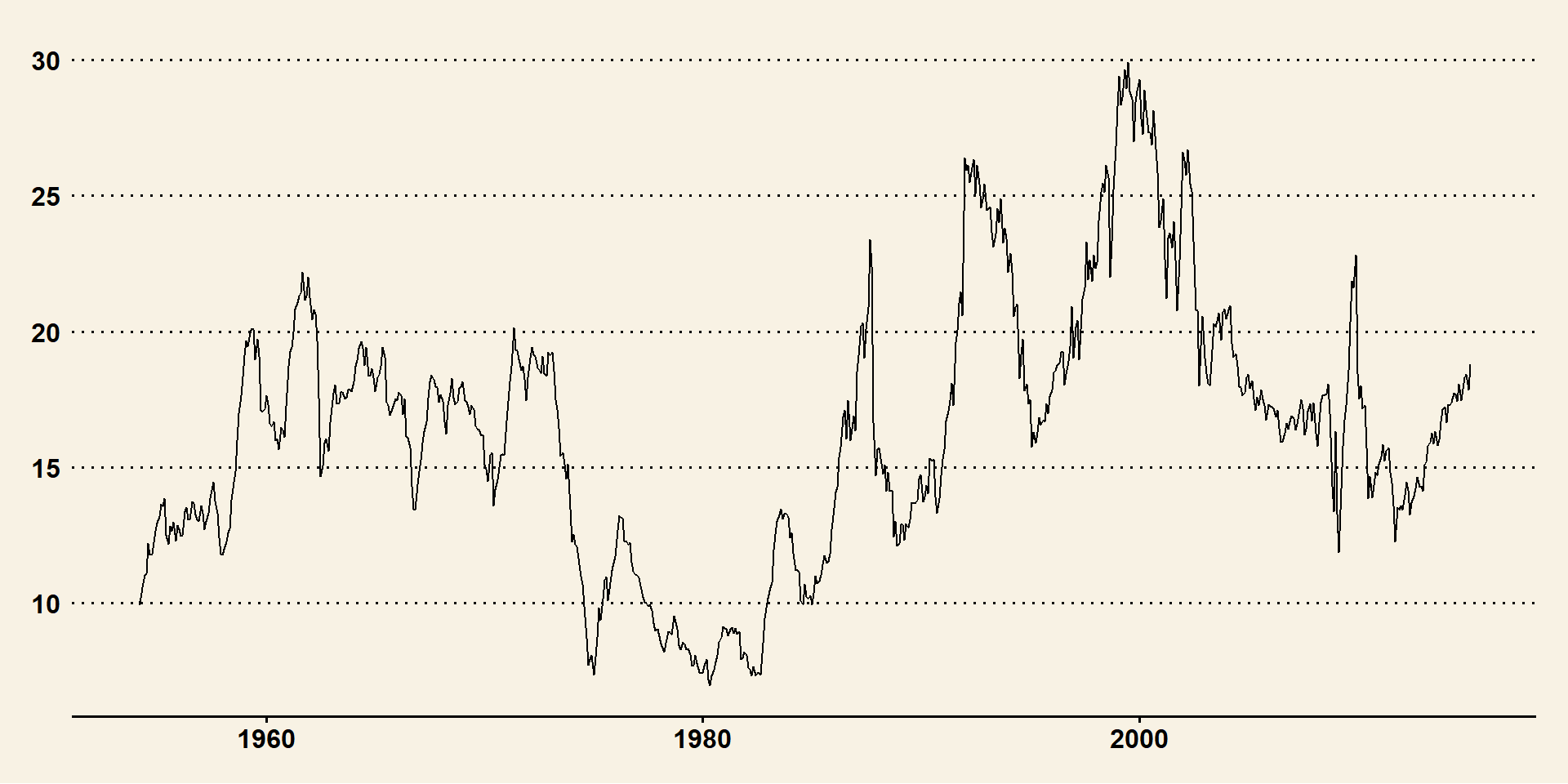
Identify model
Use SACF and SPACF to choose model(s) and also use auto.arima and see which of these two wins: your judged model or auto.arima
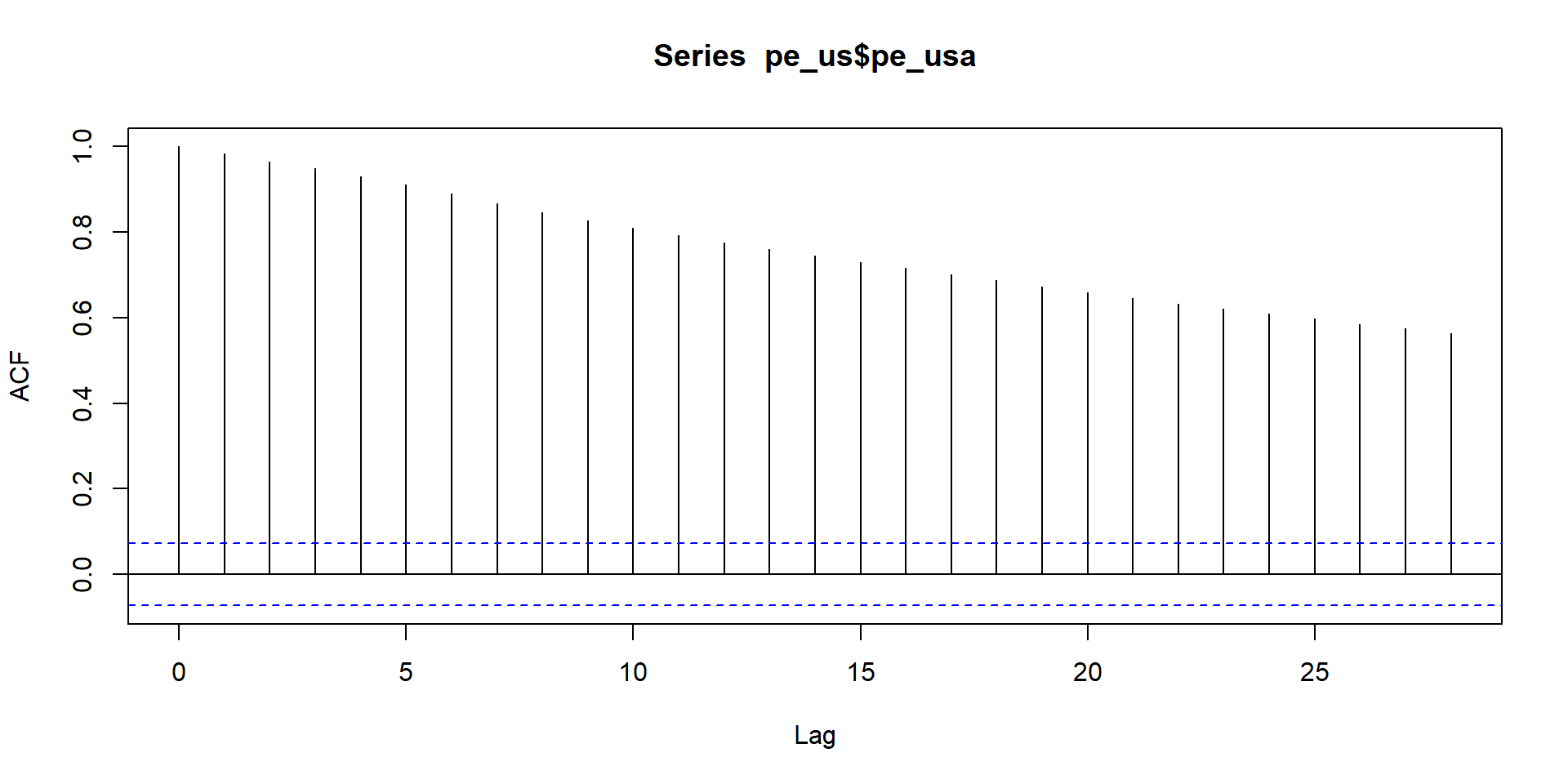
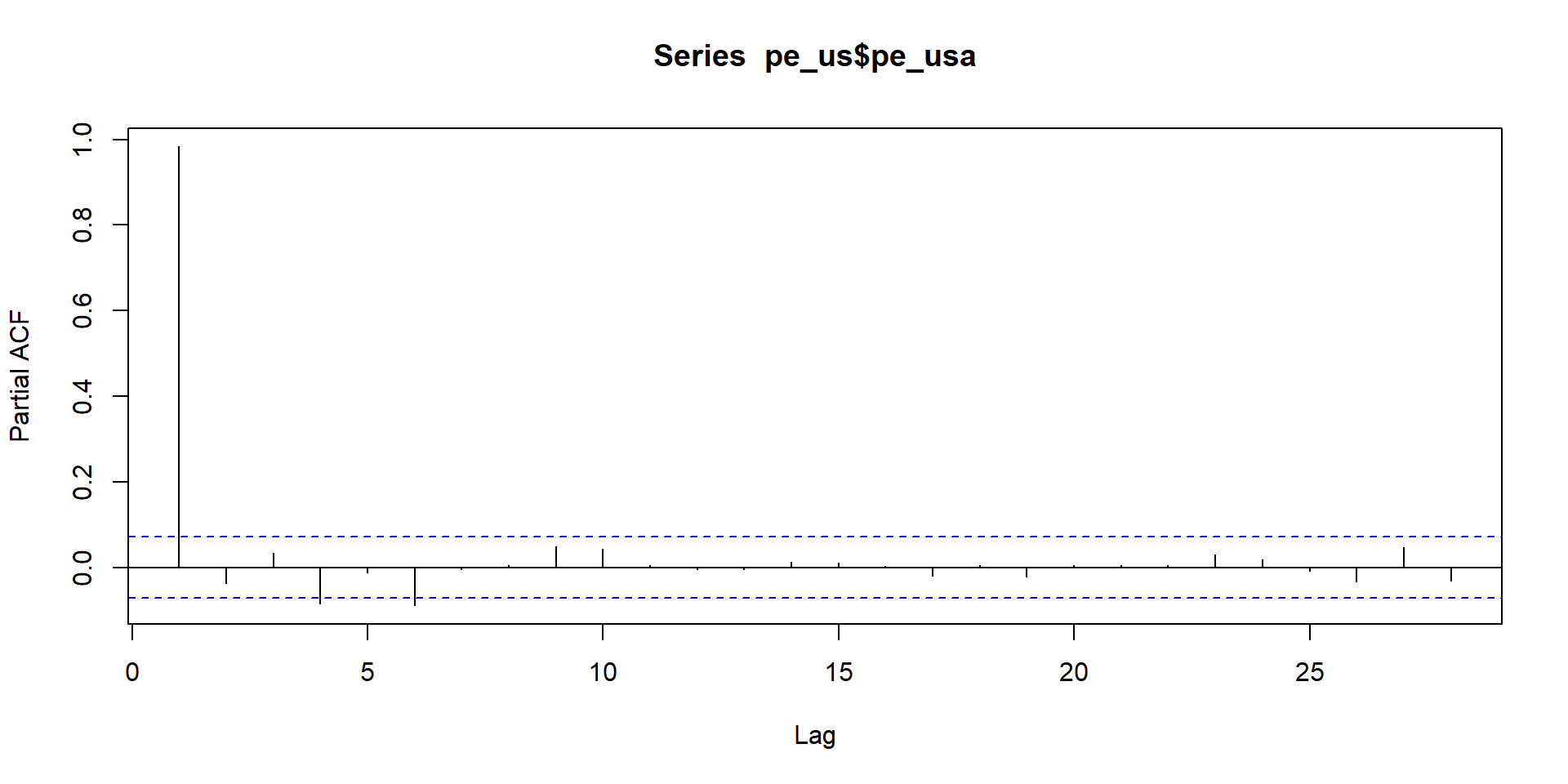
acf and pacf patterns indicate series is non-stationary. So here we run acf and pacf of difference of the series.


From these two graphs it seems model is ARIMA(0,1,1)
Series: pe_us$pe_usa
ARIMA(1,1,1)
Coefficients:
ar1 ma1
-0.7554 0.8268
s.e. 0.1106 0.0944
sigma^2 = 0.7151: log likelihood = -914.95
AIC=1835.91 AICc=1835.94 BIC=1849.69So our model was ARIMA(0,1,1) while auto.ARIMA is ARIMA(1,1,1) not bad.
Nonstationary series can have a trend:
- Deterministic: nonrandom function of time:
\(y_t=\mu+\beta t+u_t\) , where \(u_t\) is “iid”
- Example \(\beta=0.45\)